Abstract
Hand gesture serves as a crucial role during the expression of sign language. Current deep learning based methods for sign language understanding (SLU) are prone to over-fitting due to insufficient sign data resource and suffer limited interpretability.
In this paper, we propose the first self-supervised pre-trainable SignBERT+ framework with model-aware hand prior incorporated. In our framework, the hand pose is regarded as a visual token, which is derived from an off-the-shelf detector. Each visual token is embedded with gesture state and spatial-temporal position encoding. To take full advantage of current sign data resource, we first perform self-supervised learning to model its statistics. To this end, we design multi-level masked modeling strategies (joint, frame and clip) to mimic common failure detection cases. Jointly with these masked modeling strategies, we incorporate model-aware hand prior to better capture hierarchical context over the sequence. After the pre-training, we carefully design simple yet effective prediction heads for downstream tasks.
To validate the effectiveness of our framework, we perform extensive experiments on three main SLU tasks, involving isolated and continuous sign language recognition (SLR), and sign language translation (SLT). Experimental results demonstrate the effectiveness of our method, achieving new state-of-the-art performance with a notable gain.
Reconstruction Visualization
We perform qualitative reconstruction results on two types of hard cases, i.e., hand-to-hand interaction and hand-to-face interaction. Even under these hard cases, our framework can rectify the noisy inputs and infer all the poses which well align the image plane. This strong hallucination capability may be largely attributed to the well-modeled statistics in the sign language domain.

Main Results
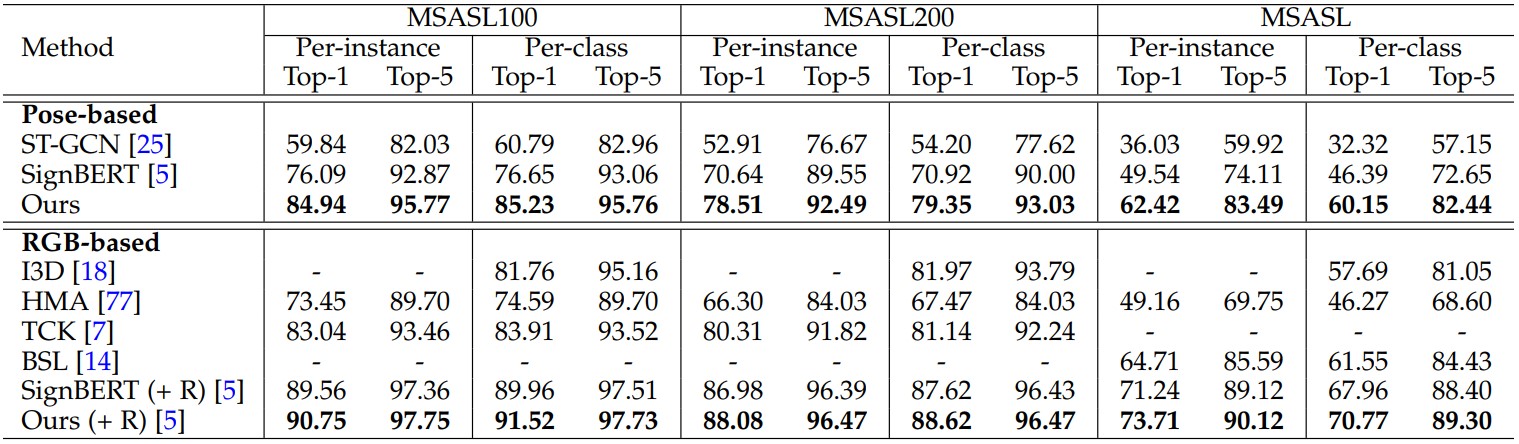
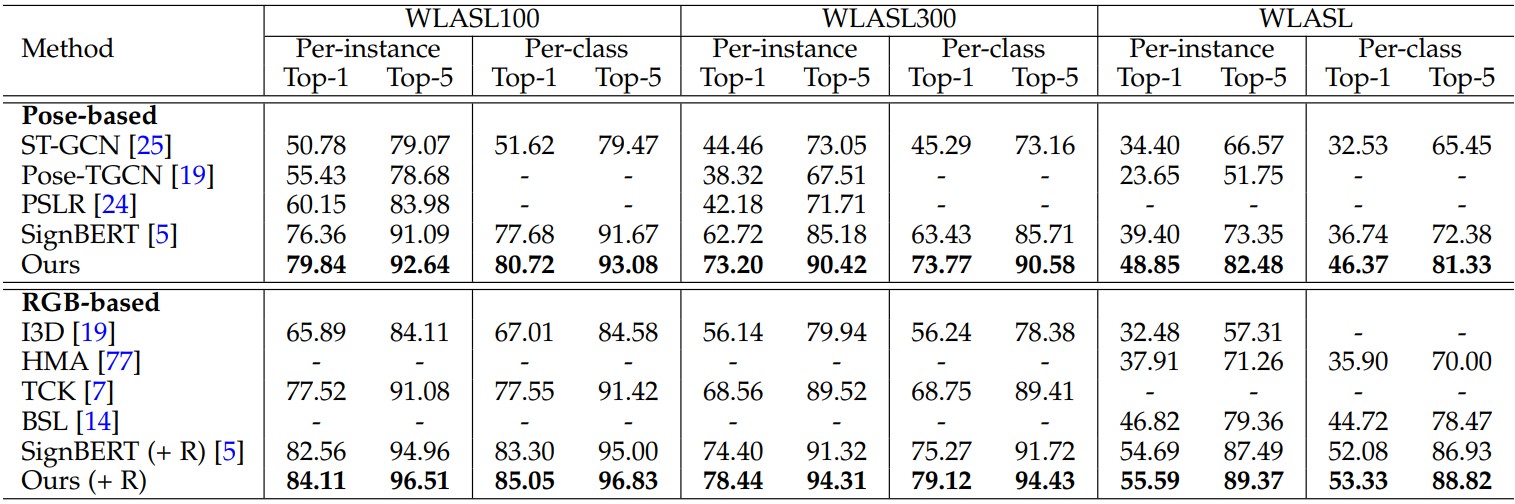
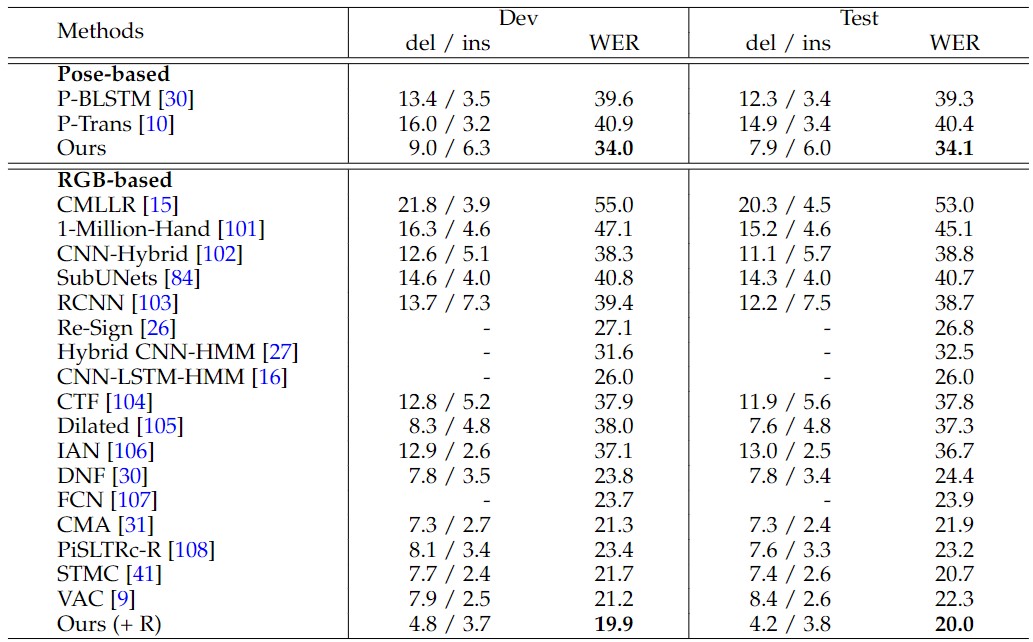
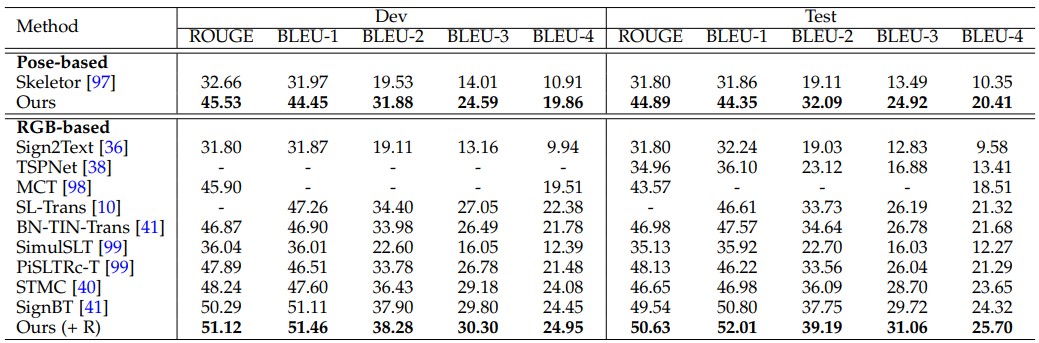
We compare our method with previous state-of-the-art methods on three main downstream tasks, including isolated SLR, continuous SLR and SLT. For comparison, we group them into pose-based and RGB-based methods.
1. Isolated Sign Language Recognition
- MSASL
- WLASL
- RWTH-Phoenix
- RWTH-PhoneixT
BibTeX
@article{hu2023SignBERT,
author={Hu, Hezhen and Zhao, Weichao and Zhou, Wengang and Li, Houqiang},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
title={SignBERT+: Hand-model-aware Self-supervised Pre-training for Sign Language Understanding},
year={2023},
pages={1-20}}